






- Apr 29, 2022
Understand How Search Engines Crawl and Index Your Website – Discover It Now!
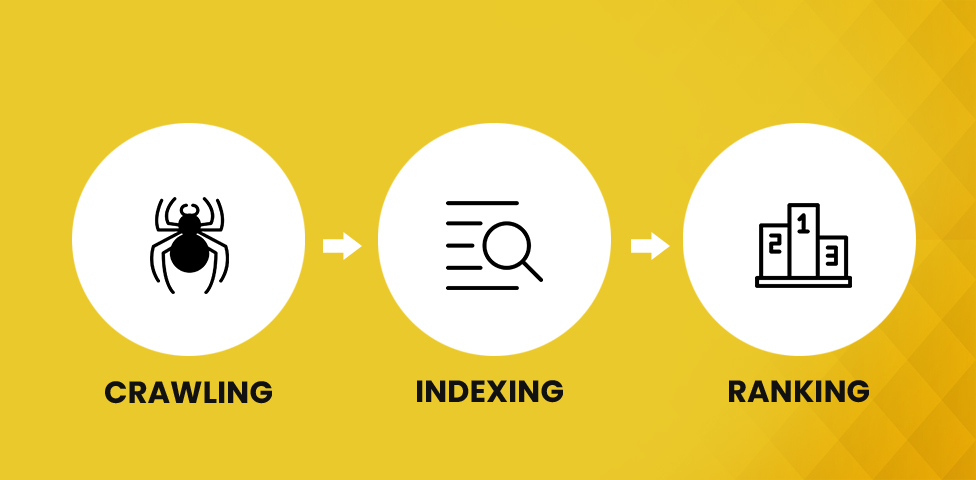
SEO or Search Engine Optimization is the practice of boosting the quantity and quality of traffic that lands on your website. Nevertheless, do you know without "crawl and index" it is not possible to do so? In other words, SEO is the process of optimizing the web pages to “organically” achieve higher search rankings by using mechanisms that can systematically browse the World Wide Web for crawling and indexing millions of webpages and websites. Now if you have never wondered what makes a search engine go around, let us have a close look at the primary function of crawling and indexing that helps in delivering optimal search results.
What Is Web Crawling
[caption id="attachment_1714" align="aligncenter" width="768"] Source: Google[/caption]
To explain it simply, crawling is the process that is performed by search engines where it uses web crawlers to find any new website, page link, landing page, or any alterations to current data, broken links, and many more. These web crawlers are also known as “bots” or just “spiders”.
Technically when the spiders visit any website, they follow the internal links through which they can land on other pages of the website.
Hence creating a sitemap (that contains a vital list of URLs) is one of the main reasons which help make it easier for the Google bots to crawl the website.
In other words, whenever the spider crawls the web pages or the website, it goes through the DOM (Document Object Model) that represents the logical tree structure of the website.
Technically speaking, DOM is the rendered JavaScript and HTML code of the pages in the website. Now as it is nearly impossible for the web engines to crawl the entire website at once, hence the bots crawl on the important parts of the website which are significant for measuring individual statistics that can help in raking the websites.
Source: Google[/caption]
To explain it simply, crawling is the process that is performed by search engines where it uses web crawlers to find any new website, page link, landing page, or any alterations to current data, broken links, and many more. These web crawlers are also known as “bots” or just “spiders”.
Technically when the spiders visit any website, they follow the internal links through which they can land on other pages of the website.
Hence creating a sitemap (that contains a vital list of URLs) is one of the main reasons which help make it easier for the Google bots to crawl the website.
In other words, whenever the spider crawls the web pages or the website, it goes through the DOM (Document Object Model) that represents the logical tree structure of the website.
Technically speaking, DOM is the rendered JavaScript and HTML code of the pages in the website. Now as it is nearly impossible for the web engines to crawl the entire website at once, hence the bots crawl on the important parts of the website which are significant for measuring individual statistics that can help in raking the websites.
How To Optimize Website For Google Crawler
At times we come across specific instances wherein you might find that the Google crawler is not crawling various crucial pages of the website. In these scenarios, it becomes necessary to tell the search engine how to crawl that specific website. To do this create and place “robots.txt” files and place them in the root directory of the domain. Robots.txt are files that help the crawlers to crawl the website in a systematic manner. This implies that the robots.txt file helps the crawler bot to understand which pages are needed to be crawled. This also helps in maintaining the Crawl Budget of the website.Key Elements That Affect The Crawl
A spider does not crawl the content if it is placed behind the login form in a webpage, or if any page needs the user to log in, as such pages are considered secured pages by the bot. The bot does not crawl the search box info present on the website. Especially for e-commerce websites. Although most people think that when a user enters the product of their liking in the search box, they get crawled by the bot. There is no guarantee that the bot will crawl media forms like audio, videos, and images. Hence it is advised to add the text of those embedded elements (as image names) in HTML. Manifestations of webpages for any particular visitor where the pages are shown to the spider different from the users are blocked to the search engine bots. Many a time the search engine crawlers detect a link to enter your web pages from other websites. However, in such a case the bot also requires the link on your website to navigate various other external landing pages. Now, pages that do not have internal links assigned to them are known as “Orphan Pages”, and so they remain next to invisible to the spiders while crawling the website. Crawlers of all search engines get frustrated and leave the pages when they stumble upon “crawl errors” on the website. For instance, errors like 404, 500, etc. Hence it is advised to either temporarily redirect the faulty webpages by performing 302 (redirect) or 301 (permanent redirect) to place a bridge for search engine bots and allow them to crawl appropriately.Here is a list of names of a few of the most talked-about “Web Crawlers” which include:
- Google Bot
- Bing Bot
- Slurp Bot
- Baidu Spider
- Yandex Bot
What Is Web Indexing
[caption id="attachment_1715" align="aligncenter" width="768"] Source: Google[/caption]
Now that we know what is Crawling, let us understand the meaning of Indexing a website.
Simply speaking as the word reveals, “index” is the compilation of all the info of the pages crawled by the search engines.
Hence indexing is the process of archiving the gathered information in the search index database, whereby the indexed data is compared with the previously stored data with complex SEO metrics and algorithms with similar pages, which helps in the process of ranking a website.
Source: Google[/caption]
Now that we know what is Crawling, let us understand the meaning of Indexing a website.
Simply speaking as the word reveals, “index” is the compilation of all the info of the pages crawled by the search engines.
Hence indexing is the process of archiving the gathered information in the search index database, whereby the indexed data is compared with the previously stored data with complex SEO metrics and algorithms with similar pages, which helps in the process of ranking a website.
How Can You Perceive What the Search Engine Has Indexed?
Let us take into account the most popular of all search engines on this planet – Google. Just type “site: your domain” in Google’s search box to check how many pages are indexed in the Google SERP. Performing this search will show all the pages the search engine has indexed which include pages, posts, images, Instagram, and more. Now, the best means to make URLs indexed is to submit the website’s site map in the Google Search Console, where all the vital pages are listed on the map. Website indexing plays a major role while displaying all the vital pages on the SERP. This means that suppose any content is not visible to the Google bot, the page will not be indexable. In reality, the Google bot visualizes the web pages in a completely different way. It sees them in different formats like CSS, HTML, and JavaScript and so the components which are not accessible do not get indexed by the search engine.How Does the Search Engine Decide What to Index?
When any user types a query, the search engine attempts to find the most pertinent answer from its already crawled pages in its database. For instance, Google indexes the content on the web pages according to its defined algorithms, which are updated and modified at a regular interval. Now, any search engine usually indexes the fresh and new content on the websites, which search engines like Google believes will improve the user experience. Therefore, the better and more unique the content, the higher ranking Google renders for the webpage as it proves better for SEO.Tips- Takeaway
As one of the best SEO company in Kolkata, we suggest you can even try using a web crawler app to get a better idea of how a search engine crawls your website. There are several web crawlers available in the marketplace. For instance, Screaming Frog is one of the most easy-to-use applications, that has a great interface and allows crawling up to 500 pages for free. Apart from it, you can also use Sitebulb or Xenu’s Link Sleuth which are also excellent tools and can quickly crawl robust websites and check their status codes or find which pages link to which other pages on the website. Our dynamic team at SB Infowaves is growing every day with their skills in digital marketing for delivering high-octane solutions to all our clients under a single umbrella at affordable prices. If you have liked the article, leave your comment below.One thought on “Understand How Search Engines Crawl and Index Your Website – Discover It Now!”
Leave a Reply
Our Office

USA
Florida
S Beach St #100 Daytona Beach, FL 32114
United States Of America

+1-4073-743-746

Australia
Sydney
Rubix Alliance Pty Ltd Suite 305/30 Kingsway, Cronulla NSW 2230
+61-1800-682-147

India
Kolkata
Adventz Infinity, Office No - 1509 BN - 5, Street Number -18 Bidhannagar, Kolkata - 700091 West Bengal
+91-8335-038-522
India
Bengaluru
KEONICS, #29/A (E), 27th Main, 7th Cross Rd, 1st Sector, HSR Layout, Bengaluru, Karnataka 560102
+91-9163-413-459

https://t.me/nifty50stockadvisor/750